
Googleの人口知能(機械学習)ライブラリ「Tensor Flow」を体験してみよう!【MNIST編】

前回までに「Tensor Flow」を導入するまでを見てきましたが、今回からはアメリカ国立標準技術研究所(NIST)が提供している「MNIST」と呼ばれている手書き文字データを利用したTensorFlowのチュートリアルを実行していきたいと思います。
実践!「Tensor Flow」チュートリアル(MNIST)
「MNIST」の手書き文字データは、1つの文字が縦28pxと横28pxで構成されています。
28pxの2乗=784個のデータで1文字を表し、1文字を1つのベクトルとして扱っていきます。
今回は、55000件のデータを学習用のデータとして利用し、Tensor Flowに学習をさせていきたいと思います。
学習用データは2種類あり、
- 学習用データ
- ラベルデータ(正解データ)
があり、ラベルデータはTensor Flowに学習させた後、正解を教えるために利用していきます。
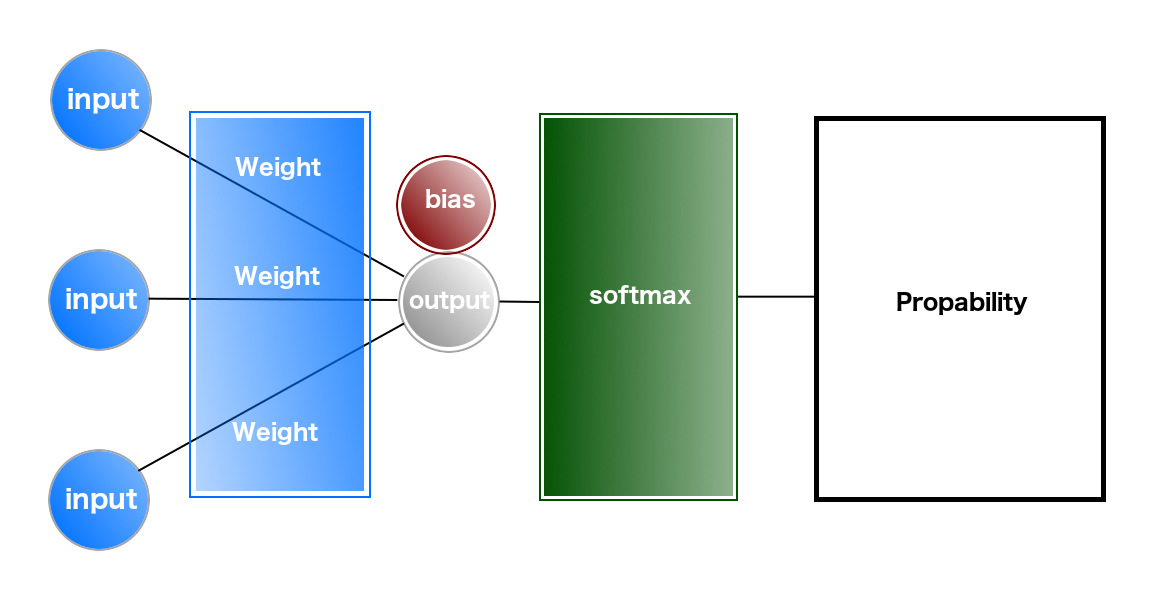
実際の学習には、「重み」「バイアス」といったパラメータが利用され、その値を元に学習結果(1から9のそれぞれの数字の確率)の出力を行なっていきます。
それでは、実際にTensor Flowチュートリアルを実行してみたいと思います。
→「Tensor Flow - Training a neural network on MNIST with Keras -」
Anacondaを起動し、Tensor Flow用のファイルを作成し、「Tensor Flow - MNIST For ML Beginners -」ページにあるコードを入力していきます。
まず、インプットデータモジュールのインポートと、学習用データ・正解データなどをダウンロードします。
ここからPython言語を利用していきますので、Pythonの知識が無い方は、初めにPythonについて学んでいきましょう。
# TensorFlowのチュートリアルのMNISTデータをインポート
from tensorflow.examples.tutorials.mnist import input_data
#MNISTデータから必要なデータを読み込む
#read_data_sets(読み込むデータ, one_hotがtrueの場合、すでに読み込むデータがあれば読み込まない)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
上記のコードを入力して実行すると、必要なデータをダウンロード後、ダウンロードデータを展開して使える状態にしてくれます。
データはバイナリデータとなっていますので、通常のテキストエディタでは中身を見ることはできませんが、バイナリエディタを使うことで、データ内容を表示することができます。
次に、Tensor Flowを利用するために、Tensor Flowモジュールをインポートし、「tf」というコードでTensor Flowが実行できるよう別名をつけておきます。
import tensorflow as tf
Tensor Flowにダウンロードしたデータを格納するための領域を用意します。
x = tf.placeholder(tf.float32, [None, 784])
「placeholder」は、データを用意するためのメソッドで、今回の場合は、「32ビット浮動小数点」のデータを入れる領域を用意しています。
「None」は入力データを指定をしないという意味があり、「784」の部分は入力データの個数を表しています。
次に「重み」と「バイアス」の値を格納するための変数を用意します。
W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10]))
「zeros」メソッドは、値を「0」で埋める「0埋め」をするためのメソッドです。
「入力値」「重み」「バイアス」から出力値を計算します。
y = tf.nn.softmax(tf.matmul(x, W) + b)
正解データを格納する変数を用意します。
y_ = tf.placeholder(tf.float32, [None, 10])
「計算した出力値」と「正解データの値」から「誤差を最小にするための値」を計算します。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
「クロスエントロピー(交差エントロピー)」という「誤差関数(損失関数)」を用い計算を行なっていますが、詳しく知りたい方は下記をご覧ください。
次にトレーニングを行い、「重み」を更新していきます。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
ここでは、「勾配降下法」という手法を使用し、最適な値を求めています。
「GradientDescentOptimizer」のパラメータ「0.5」は「学習率」を表しています。
「学習率」は勾配降下法で重みを更新するときの「更新量」を表していて、0〜1未満の値を設定しますが、あまりに値が小さいと更新量が小さく計算回数が増えてしまいます。
次に計算を行うための初期化と準備を行います。
#計算の準備 sess = tf.InteractiveSession() #値の初期化 tf.global_variables_initializer().run()
次はいよいよトレーニングを実行しますが、「100個のランダムデータ」で「1000回トレーニング」を行います。
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
トレーニングを行なった結果の「精度」を求めていきます。
#計算結果の精度を求めて表示
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
これで、最後に予測精度の結果が表示されるようになります。
Tensor Flowでは、このような文字を使った「入力文字の予測」を行うことや、他にも静止画や動画の変換なども行うことができますので、興味があれば引き続きさまざまなTensor Flowの機能に触れてみてはいかがでしょうか。